
声波是声音的传播形式,发出声音的物体称为声源。 声波是一种机械波,由声源振动产生,声波传播的空间就称为声场。 声波传递信息的一些典型例子:声波投屏、声波支付等。
声音是一种机械波,拥有波动传播的性质,如频率、波长、振幅等:
人耳能听见的声音频率在20~20000Hz之间,超过人类耳朵可以听到的最高阈值20kHz的声波也叫超声波,因此可以利用接近20000Hz频率的声音来传递信息。
在电子设备中,可以发出声波的元件可以是扬声器,蜂鸣器,可以接收声波的元件是mic。通过mic振动产生的信号是模拟信号,而计算机处理或存储声音信息需要使用数字信号,所以模数转换就是必须经过的一道步骤。WAV是一种常见的记录声音波形的文件格式,它能记录声音的采样位数、采样频率、声道数等信息,这些信息反映了声音的波动状态、频率范围、立体感等特征。其中采样就是将声音信号数字化的过程。
这里选择使用最简单的方案编码信息,就是通过不同的频率代表不同的字符信息。环境中接近20000Hz频率的声音是较少的,比较容易区分。假设我们在T时刻从mic接收声音,那么随着时间变化,我们可以获得T+1、T+2 ….之间的每一段音频,对每段音频进行解码,分析其中的频谱,就可以知道该段中是否存在目标频率。

我们通过麦克风采集的信号其实是基于时间的,例如我们T时刻从mic中读取1024个采样到缓冲区,其实读取到的就是1024个振幅的值。
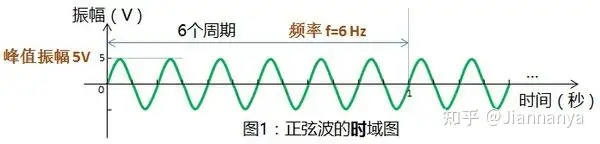
时域中自变量是时间,即横轴是时间,纵轴是信号的变化。其动态信号x(t)是描述信号在不同时刻取值的函数。
以下代码可以读取1024个采样点到一个缓冲数组中,其中每个点是一个int16值,也就是y坐标。如果用 16bit 采样深度和 44100 的采样频率,那么1s的声音采样就是一个 44100 大小的 int16 数组。
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=44100, input=True, frames_per_buffer=1024)
try:
while True:
audio_data = stream.read(1024, exception_on_overflow=True)
audio_frames = np.frombuffer(audio_data, dtype=np.int16)
print(len(audio_frames))
break
except BaseException as e:
print(e)
如果mic中收到的只有我们发出的波,那么直接计算就能知道这一段波的频率,从而得到对应的信息。问题在于mic中收到的声波是许多不同频率的波叠加形成的波,从时域图里看根本无法区分到底这段波形是由多少不同频率的波组合成的,因此需要拆解复合的波形,了解这个波的组成。
要拆解波形,就需要将时域改为频域来分析波形的组合。频域是把时域波形的表达式做傅立叶等变化得到复频域的表达式,所画出的波形就是频谱图,是描述频率变化和幅度变化的关系。频域的自变量是频率,即横轴是频率,纵轴是该频率信号的幅度,也就是通常说的频谱图。

通过观察频谱,就可以知道某频率上是否存在能量,如果该频率能量超过某个数值,就认为我们的发射源发射了该频率的声波(例如在19000Hz附近出现较高的幅度),但是这里的能量并非物理意义上的能量,它用来表示该频率信号对原始信号的贡献。